Why Google Disabled io_uring
Exploring what io_uring is, Google’s exploit programme and the major reasons

Introduction
In recent years, the Linux kernel’s asynchronous-I/O interface io_uring has been hailed as a performance breakthrough. But for large-scale, high-security environments like Google’s, it has also become a significant headache. In June 2023, Google publicly warned that io_uring “provides strong exploitation primitives” and restricted or disabled its use on many of its platforms.
In this article, we look at what io_uring is, summarise Google’s exploit/bug-bounty findings, outline why Google pulled back on it, and conclude with thoughts on how io_uring should ideally work and areas for improvement.
What is io_uring? (a basic overview)
At its simplest, io_uring is an API in the Linux kernel that allows high-performance asynchronous I/O by submitting I/O requests into a ring buffer and then getting completions via another ring buffer, thereby reducing system-call overhead, context-switching, and improving throughput.
Key features include:
Submission ring + completion ring model
Support (over time) for both files and network sockets
Efficient polling and direct I/O support which reduces latency
Better utilisation of NVMe, SSDs, high-speed storage and high-rate networking
From a performance standpoint, for workloads that issue many asynchronous I/O requests (databases, high-throughput servers, network services) io_uring can markedly reduce overhead compared to older AIO or synchronous-I/O models.
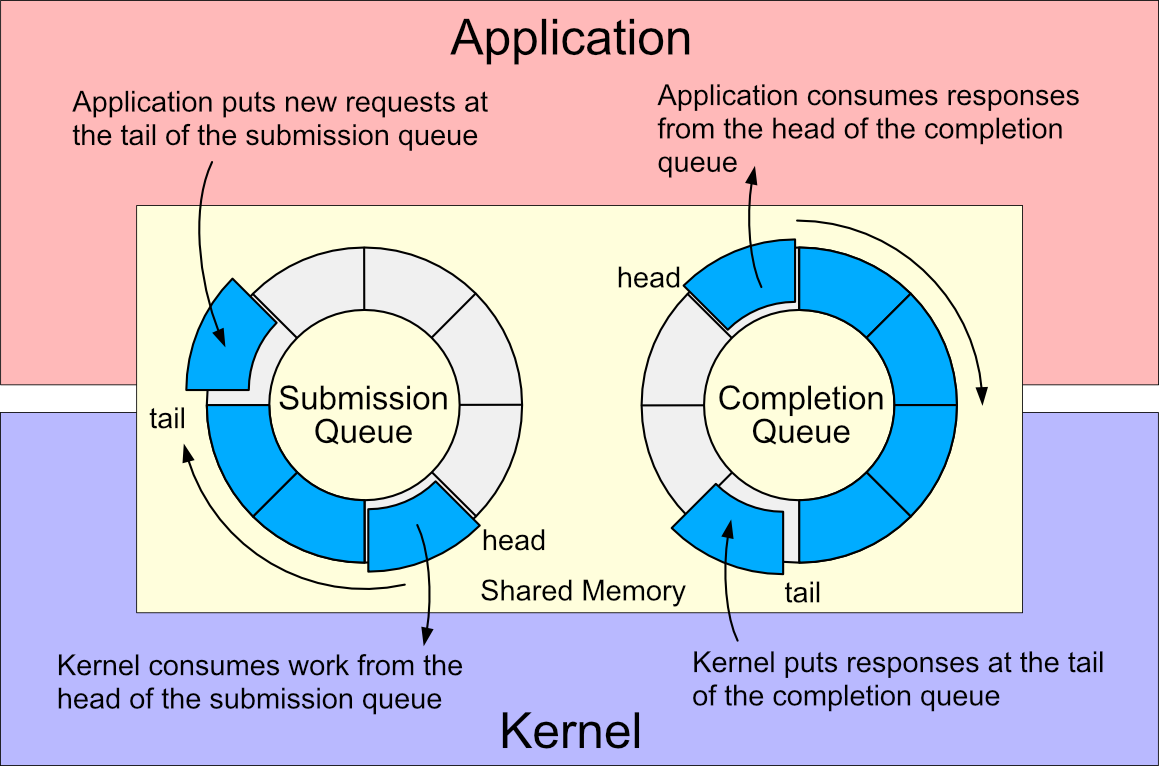
However – and this is the crux – with great power comes greater complexity. The kernel subsystem is large, manages direct memory, multiple ring-structures, concurrency, and it interacts with many parts of the kernel. This in turn increases the “attack surface” for bugs and exploits.
Google’s exploit findings & bug-bounty programme
Google’s security team (via their Linux kernel-exploit bug-bounty programme) reported some telling statistics and actions:
According to their blog post, since its inception the programme has rewarded researchers with total of US$1.8 million.
In the past year, around 60% of all kernel exploit submissions were tied to the io_uring component of the Linux kernel.
Google also reports that they paid out roughly US$1 million in rewards specifically for io_uring-related kernel exploits.
As a result, Google decided to limit the usage of io_uring in their products:
On ChromeOS: io_uring is disabled.
On Android: Use of io_uring by apps is blocked via seccomp-bpf filters; future releases will use SELinux to limit io_uring access to selected system processes.
On Google production servers and GKE autopilot: io_uring is disabled or under investigation for disabling by default.
The blog post states:
“While io_uring brings performance benefits … it is a fairly new part of the kernel. As such, io_uring continues to be actively developed, but it is still affected by severe vulnerabilities and also provides strong exploitation primitives. For these reasons, we currently consider it safe only for use by trusted components.” Google Online Security Blog
These findings paint a clear picture: for Google, io_uring was simply too risky in many large-scale, multi-tenant, production-critical contexts.
Major reasons why Google disabled/restricted it
Here are the key reasons which I feel may lead to Google disabling it:
1. Large number of kernel exploits via io_uring
When 60% of kernel exploit submissions are tied to one subsystem, that subsystem becomes a critical risk point. Google’s bug-bounty costs for io_uring demonstrate the severity as mentioned in the source blog.
2. Strong exploitation primitives
By design, io_uring manipulates kernel resources (rings, submission/completion buffers, direct I/O, memory mapping etc). That means that bugs can more easily lead to local privilege escalation (LPE), container breakout, host compromise. Indeed Google noted that io_uring “provides strong exploitation primitives”. Reference Security Blog
3. Newer code, rapidly evolving, complex concurrency
io_uring is relatively new (initial versions appeared around Linux 5.x), and though performance-optimised, it is code-intensive, with many moving parts (threads, polling, async submission, memory mapping). This complexity magnifies risk. Google’s blog acknowledges that it is “a fairly new part of the kernel … it is still affected by severe vulnerabilities.” Reference Blog
4. Multi-tenant, large-scale production context amplifies risk
Google’s environment is extremely demanding: thousands of servers, containers, high-throughput services, many untrusted workloads (apps, tenants). A vulnerability in io_uring in such context can cascade into massive damage (root compromises, container breakout, privilege escalation). Therefore their tolerance for risk was extremely low.
5. Insufficient isolation/sandboxing for io_uring in untrusted workloads
Even if io_uring’s bugs are fixed, using it across untrusted code paths (third-party apps, containers) needs strong sandboxing. Google’s decision shows that in its view, such isolation was not yet sufficient in many contexts. By disabling it for untrusted components and restricting to “trusted components”, Google hedged risk.
6. Strategic decision: disable first, enable later when safe
Rather than allowing full usage and reacting to each bug, Google took the proactive position of disabling or restricting io_uring until they felt safe in their environment. This is a risk-management stance.
How io_uring should work and areas of improvement
Given its performance benefits, it would be unfortunate for io_uring to be abandoned entirely. Instead, here are suggestions I feel should be implemented, especially in environments similar to Google’s:
Suggested usage model
Restrict io_uring to trusted components (system services, kernel teams, known workloads) rather than arbitrary third-party or untrusted code.
Use seccomp-bpf filters, SELinux policies, capability restrictions to control who can call io_uring APIs.
Introduce permissions or syscall filtering for io_uring APIs, to limit ring set-ups, submission queue size, memory mapping, etc.
Monitor and log all io_uring usage (ring creation, submission, completion) for anomaly detection.
Provide fallback options (synchronous I/O, older AIO) for untrusted / lower-performance workloads until io_uring is vetted.
Areas of improvement (for the kernel / community)
Harden the API and implementation: reduce concurrency hazards, race-conditions, use-after-free, memory corruption, fixed-file issues, etc.
Reduce the attack surface: Provide smaller-capability versions of io_uring (e.g., limited ring sizes, restricted operations, mandatory bounds checks).
Better sandboxing support: Ensure io_uring interacts safely with namespaces, cgroups, seccomp, containers.
Audit and fuzzing: Increase fuzz-testing coverage for io_uring API, especially for new kernel versions. Build monitoring tooling that tracks misuse.
Clear documentation & best practices: Provide kernel and distro maintainers with guidelines for safe deployment of io_uring in multi-tenant/containerised systems.
Feature gating: For new/advanced features of io_uring (e.g., shared submission queues, multi-process polling), provide optional disablement or controlled rollout in production before enabling widely.
Conclusion
In summary, io_uring represents a significant leap forward in asynchronous I/O performance on Linux, and for many workloads it is highly beneficial. But for organisations like Google operating at massive scale with extremely low tolerance for kernel-exploitation risk, io_uring has been seen as too risky—leading to its disabling or severe restriction.
This does not mean io_uring is fundamentally flawed, but rather that it requires maturity, extensive hardening, sandboxing and controlled deployment before it can be safely used across untrusted workloads.
Going forward, the path is clear: use io_uring where the risk is managed (trusted code, fewer layers of abstraction), and continue the kernel/OS ecosystem’s work in improving its safety. With time, as the API and its ecosystem mature, a broader safe-usage model will likely emerge.
If you’re a systems person, kernel developer or operator of large container-platforms, this is a reminder: performance features often bring increased complexity and risk, and the safe deployment of such features demands more than just “turn it on”.

